
從訓練到推理:創建用于圖像識別的神經網絡
傳統的圖像處理軟件依賴特定任務的算法,而深度學習軟件是利用網絡實現的用戶訓練算法,來識別好的和壞的圖像或區域。
幸運的是,訓練神經網絡的專用算法和圖形用戶界面(GUI)工具的出現使生產商能夠以更輕松、更快速、更實惠的方式進行神經網絡訓練。生產商可以從深度學習GUI工具中得到什么?使用這些工具有何感受?
1、訓練:創建深度學習的模型
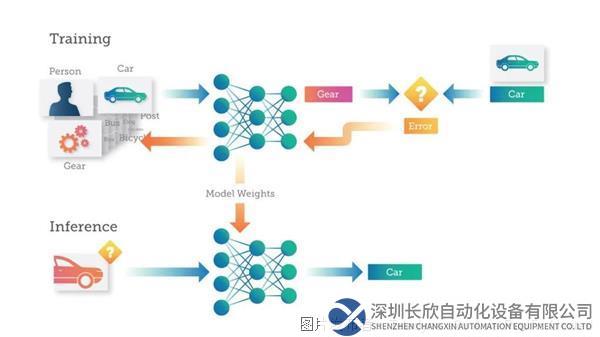
訓練是通過向深度神經網絡(DNN)提供可以學習的數據來“教授”深度神經網絡(DNN)執行所需任務(例如圖像分類或將語音轉換為文本)的過程。DNN對數據代表的內容進行預測。然后將預測中的錯誤反饋給網絡,升級人工神經元之間的連接強度。收到的數據越多,DNN學到的內容就越多,直到DNN做出的預測能達到預期的準確性水平。
例如,考慮訓練一個DNN,該DNN的目的是將圖像識別為三個不同類別之一——人、汽車或機械齒輪。
通常情況下,使用DNN的數據科學家將會形成一個預先組裝的訓練數據集,這個數據集由數千張圖像組成,每張圖像都標記為“人”、“汽車”或“齒輪”。這個數據集可以是一個現成的數據集,比如谷歌的Open Images,其中包括900萬張圖像、近6000萬張圖像級標簽,以及其他更多內容。

谷歌Open Images中的注釋方式:圖像級標簽、邊界框、實例分割和可視化關系。
如果數據科學家的應用對于現有解決方案來說過于專業,那么可能需要構建自己的訓練數據集,收集和標記最能代表DNN需要學習的圖像。
訓練過程中,每張圖像會被傳遞至DNN,然后DNN會對圖像所代表的內容進行預測(或推斷)。每個錯誤都會反饋給網絡,從而提高在下一次預測中的準確性。
此處的神經網絡預測一張“汽車”的圖像是“齒輪”。然后,這種錯誤通過DNN進行回傳,網絡內的連接會得到更新,進行錯誤糾正。下次將相同的圖像提交至DNN時,DNN很可能會做出更正確的預測。
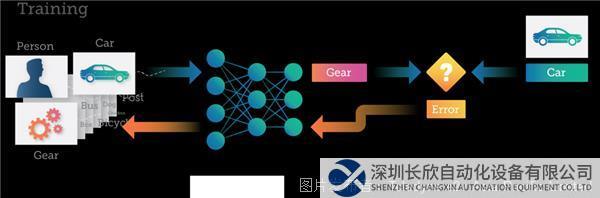
這種訓練過程繼續進行,圖像被輸入至DNN,權重得到更新,進行錯誤糾正,反復不斷地重復這個過程數十或數千次,直到DNN能夠以所需的準確度進行預測。這時,將認為DNN“經過訓練”,并且生成的模型可以用于對新圖像進行分類。
2、調整神經網絡
神經網絡的輸入、隱藏層和輸出的數量高度依賴于你要解決的問題和你的神經網絡的特定設計。訓練過程中,數據科學家試圖引導DNN模型達到預期的準確度。這通常需要運行多次甚至數百次實驗,嘗試進行不同的DNN設計,這些設計因神經元和層數的不同而不同。
輸入和輸出之間是神經元和網絡的連接——隱藏層。對于許多深度學習項目來說,1-5層神經元就已夠用,因為只評估少數特征來進行預測。但是,任務更復雜、變量和考慮因素更多的情況下,需要更多層神經元。處理圖像或語音數據可能需要數十到數百層的神經網絡(每層執行特定的功能),以及與神經網絡連接的數百萬或數十億個權重。
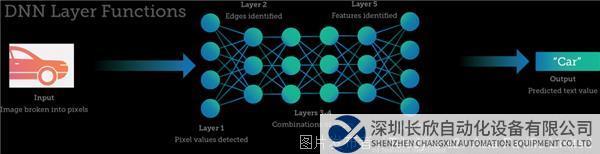
多層DNN簡化示例,其中包含各層可能執行的任務類型。
3、從樣本采集開始
一般需要數百甚至數千張手動分類的圖像來訓練系統并創建具有高度可預測性的對象分類模型。但事實證明,采集并注釋如此復雜的數據集是開發過程中的一大障礙,阻礙了深度學習在主流視覺系統中的采用。
深度學習非常適用于光照、噪聲、形狀、顏色和紋理等變量常見的環境。一個展示深度學習優勢的實際示例是對拉絲金屬等紋理表面的劃痕進行檢測。有些劃痕亮度不夠,對比度接近紋理背景本身。因此,傳統技術通常無法可靠定位這些類型的缺陷,尤其在不同樣本的形狀、亮度和對比度各不相同的條件下。圖1說明了金屬片材的劃痕檢測。通過熱圖圖像清楚顯示缺陷,突出顯示缺陷位置的像素。
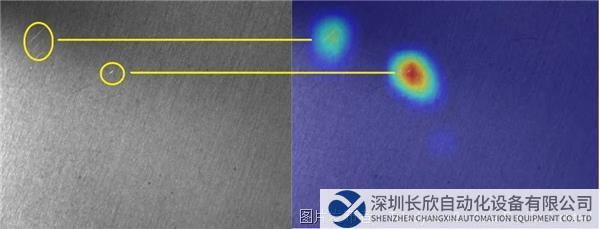
表面檢查顯示的是左側有劃痕的拉絲金屬板,分類算法輸出的熱圖顯示的是右側缺陷。其中分類算法在用輸入樣本訓練神經網絡時自動生成。需要注意的是,我們添加了黃色圓圈來顯示原始圖像和熱圖之間的對應關系。
從頭開始訓練的深度神經網絡通常需要采集數百甚至數千張圖像樣本。然而,當今的深度學習軟件通常經過預訓練,因此用戶可能只需要采集數十個額外的樣本就可以使系統適應特定的應用。
與此相反,使用常規分類構建的檢查應用需要采集“優質”和“劣質”圖像進行訓練。但使用異常檢測等新型分類算法時,用戶可以只訓練優質樣本,只需要少量劣質樣本進行最終測試。
雖然圖像樣本采集并無捷徑可走,但過程已經越來越簡單化。如需采集圖像,技術人員可使用Sapera LT,這是一款免費的圖像采集和控制軟件開發工具包(SDK),可以用于Teledyne DALSA的2D/3D相機和圖像采集卡。訓練神經網絡使用的GUI工具Astrocyte可以與Sapera LT接口連接,從相機中采集圖像。例如,用戶在手動模式下采集PCB組件上的圖像時,會用手移動PCB,改變相機的位置、角度和距離,從而生成PCB組件的一系列視圖。
4、利用視覺工具訓練神經網絡
用戶獲得圖像后就應進行神經網絡訓練。只需單擊“訓練”(Train)按鈕即可在Astrocyte中進行訓練,使用默認超參數開始訓練過程。用戶可以修改超參數,以便最終模型實現更高的準確性。
如需驗證準確性,用戶可以使用一組不同的圖像來測試模型,并選擇使用診斷工具,例如分類模型的混淆矩陣。混淆矩陣是一個NxN表格(其中N=類別個數),顯示每個類別的成功率。在這個示例中(見圖2),顏色編碼用于表示模型的精度/召回率,綠色表示精度/召回率超過90%。
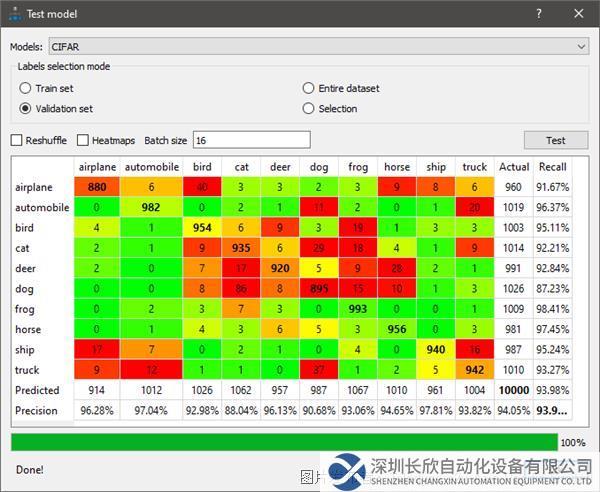
在混淆矩陣中,雙擊結果字段會打開Astrocyte圖像選項卡中的相關圖像,以便進行進一步研究。
另一個非常重要的診斷工具是熱圖。例如,進行異常檢測時,熱圖會突出顯示缺陷的位置。看到熱圖后,用戶會根據適當原因評估圖像質量的優劣。如果圖像質量很好但卻被歸類為劣質圖像,用戶可以查看熱圖獲取更多詳細信息。神經網絡將遵循用戶提供的輸入內容。
一個很好的示例是在螺絲檢查應用中使用熱圖:

Astrocyte通過相應熱圖顯示右上方圈出的缺陷。左上角顯示的是完美的圖像。
熱圖還可以揭示模型側重的圖像細節或特征,這些細節或特征與圖像目標場景或對象的期望分析無關。根據Astrocyte模塊,可以使用不同類型的熱圖生成算法。
5、運行GUI工具
解釋深度學習GUI工具方法的最佳方式是進行展示。異常檢測模型訓練是訓練神經網絡的基礎,因此這里提供了一個簡短的教程,其中包含使用Astrocyte逐步進行異常檢測的方法。
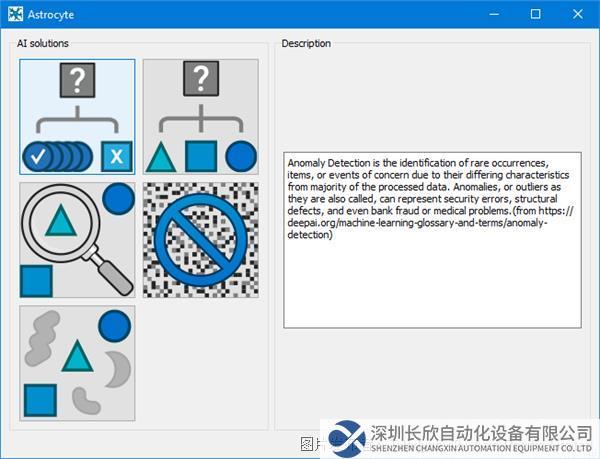
第1步:啟動Astrocyte應用程序,在啟動界面選擇“異常檢測”(Anomaly Detection)模塊:
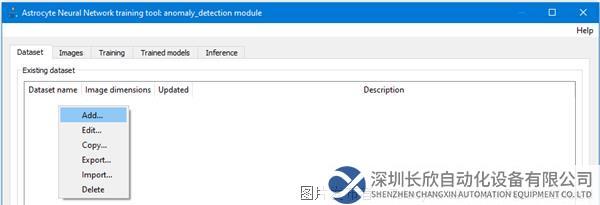
第2步:在“數據集”(Dataset)選項卡中,右鍵單擊并選擇“添加數據集”(Add Dataset)。
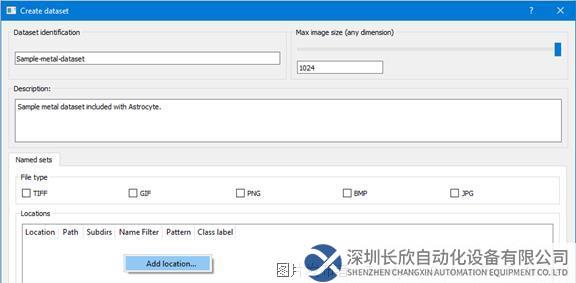
第3步:輸入數據集名稱和描述,在“數據庫”(Databases)面板中右鍵單擊選擇“添加數據庫”(Add Database)。
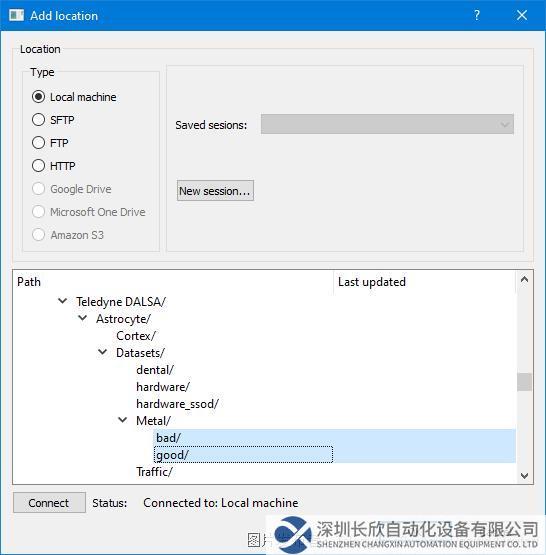
第4步:在“添加“(Add)位置對話框中,導航到包含訓練圖像數據集的文件夾。同時選擇正常(好)和異常(壞)目錄,然后單擊OK。
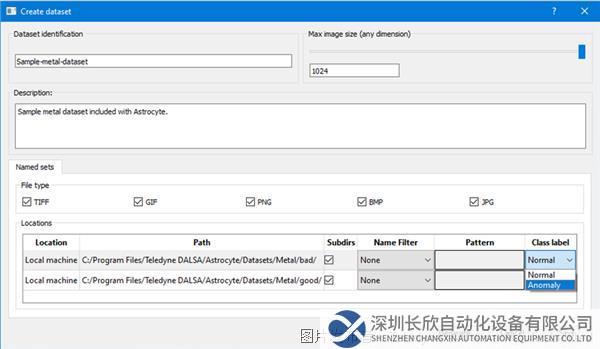
第5步:每個目錄均使用下拉列表分配類標簽:“正常”(Normal)或“異常”(Anomaly)。然后單擊“生成”(Generate)將數據集添加至內部Astrocyte服務器。
生成過程完成后,如果數據集中的圖像大小不同,則會顯示圖像大小分布分析儀對話框;否則,如果圖像大小相同,會自動調整到指定的最大圖像大小,對話框不會顯示。如有必要,使用“圖像校正”(Image Correction)對話框來校正圖像。
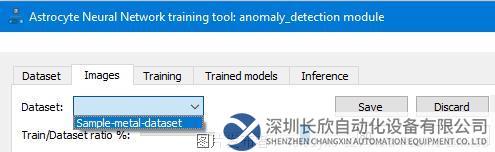
第6步:在“圖像”(Image)選項卡中,使用“數據集”(Dataset)下拉列表選擇所需的數據集。然后驗證數據集圖像和標簽,并進行必要更改。如果修改數據集,單擊“保存”(Save)更新并保存Astrocyte服務器上的數據集。
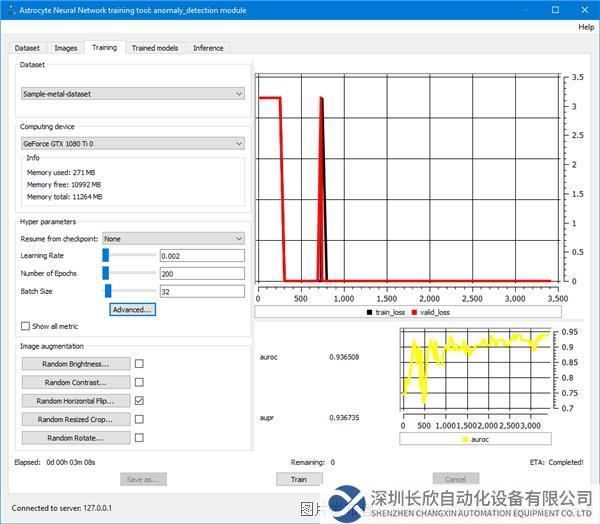
第7步:在“訓練”(Training)選項卡中,選擇數據集并單擊“訓練”;在每批完成時更新訓練損失和度量圖,并顯示訓練統計數據。
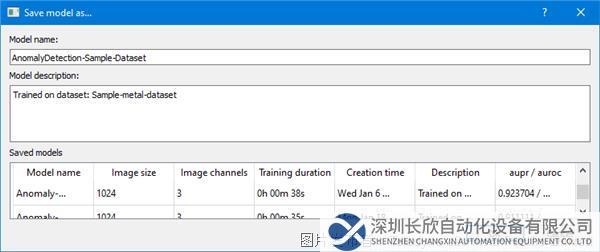
第8步:訓練完成時,會顯示一個保存模型的提示,單擊“是”(Yes)。輸入模型名稱和描述,然后單擊OK。現在您可以使用模型進行測試。Astrocyte也使用同樣直觀的GUI引導用戶完成這個過程。
6、優化推理我們需要完善受訓者嗎?
一旦以可接受的準確度水平完成訓練,我們就會得到一個加權神經網絡——本質上是一個龐大的數據庫。這個數據庫使用效果良好,但在速度和功耗方面可能不會達到最佳效果。有些應用無法容忍高水平的延遲:例如智能交通系統甚至自動駕駛汽車。自主無人機或其他電池供電系統可能需要在較小功率范圍內運行以滿足飛行時間需求。
DNN越大、越復雜,訓練和運行所消耗的計算、內存和能量就越多。因此可能不適用于您的給定應用或設備。在這種情況下,需要在訓練后簡化DNN,從而降低功耗和延遲,即使這種簡化會導致預測準確性略微降低。
在深度學習中,這種優化是一個相對較新的領域。芯片和AI加速器供應商通常會創建
SDK來幫助用戶執行此類任務——使用專門針對特定架構調整的軟件。涉及的芯片范圍很廣,包括GPU、CPU、FPGA和神經處理器。每種芯片都有自己的優勢。例如,英偉達的TensorRT突出了公司在GPU核心方面的專業性。相比之下,Xilink的Vitis AI支持公司的SoC,例如Versal,包括CPU、FPGA和神經處理器。
供應商通常會提供兩種變通方法:修剪和量化。修剪是指刪除對最終結果貢獻較小的神經網絡部分的操作。這一操作可以減小/降低網絡的大小/復雜性,但不會顯著影響輸出精度。第二種方法是量化——減少每個權重的位數(例如,用FP16或量化INT8/4/2替換FP32)。執行復雜難度較低的計算,可以提高速度和/或減少所需的硬件資源。
7、投入生產:轉向推理
一旦我們的DNN模型完成訓練和優化,就可以投入使用:針對以前看不見的數據進行預測。和訓練過程一樣,圖像作為輸入,DNN嘗試對其進行分類。Astrocyte。
Teledyne DALSA提供Sapera Processing和Sherlock兩個軟件包,其中包括一套圖像處理工具和一個用于運行人工智能模型的推理引擎。
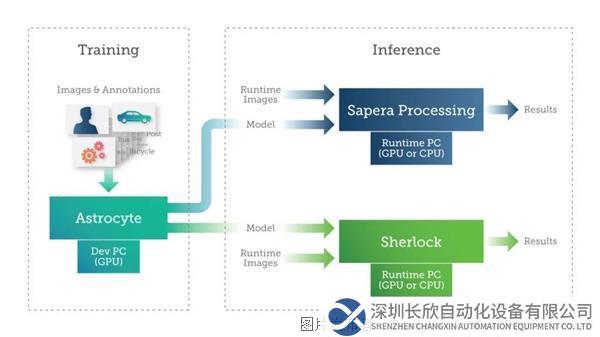
Teledyne DALSA AI訓練和推理用軟件包
用戶可以在使用GPU或CPU的PC或嵌入式設備上實現推理。根據應用的尺寸、重量和功耗(SWAP)需求,用戶可以利用各種技術在嵌入式設備(如GPU、FPGA和專用神經處理器)上實現深度學習推理。
8、深度學習:日益簡化?
從本質上講,神經網絡是復雜難懂但功能強大的工具。幾乎有無限機會來調整和優化每一個神經網絡,以最佳方式解決您的特定問題。廣泛的優化范圍以及新研究和工具的快速發展可能會讓人不知所措,即使經驗豐富的從業者也不例外。
但這并不意味著您無法將這些工具的優勢融入到您未來的視覺系統中。向GUI工具的演變正在使視覺系統中的深度學習民主化。借助將用戶從AI學習和編程的嚴格要求中解放出來的軟件,制造商可以使用深度學習來更好地分析圖像,效果超過任何傳統的算法。不久的將來,與我們傳統的檢查員相比,這種類型的GUI工具表現可能會更出色。






同類文章排行
- 萬馬高分子助力,國內首條公里級大長度環保
- 主營產品有哪些?
- 購買后產品發什么快遞?
- 節能轉型,電機產業鏈有哪些變革性機會?
- 更緊湊而高效的機器人世界
- 機器手臂的創新應用:輕薄短小、智能高效
- 產品供貨周期需要多久?
- 當半導體碰上 AMR,來一場智能化的精彩
- 堅持科技是第一生產力
- 通向智能工廠的硬核技術,哪些和你有關?
最新資訊文章
- 英孚康是羅克韋爾的替代品?不止如此
- 歐洲航天局利用MVG設備大幅增強新型 H
- Profinet轉canopen網關連接
- DATALOGIC得利捷 | 物流之眼利
- 施耐德電氣與標領智能裝備強強聯合,共創電
- 【有現貨】KB-LS10N-C KB-L
- 華北工控打造網安專用主板,基于飛騰D20
- PLC通訊革新:EtherNetIP轉P
- 華北工控ATX-6152:高度集成化!提
- 巴斯夫成功完成Ethernet-APL試
- HRPG-1000N3 系列:1000W
- RQB60W12 系列:60W 1/4
- NPB-450-NFC 系列:450W
- VFD 系列:150W~750W 工業用
- NGE12/18 系列:12W/18W
- 工業現場ModbusTCP轉EtherN
- DJM / FT系列:12V/38~15
- SI06W8/DI06W8 系列:超寬壓
- NGE100 (U) 系列:100W 環
- LOP-200/300系列:200W &